Natural Language Processing
Learning to Reason Over Tables from Less Data
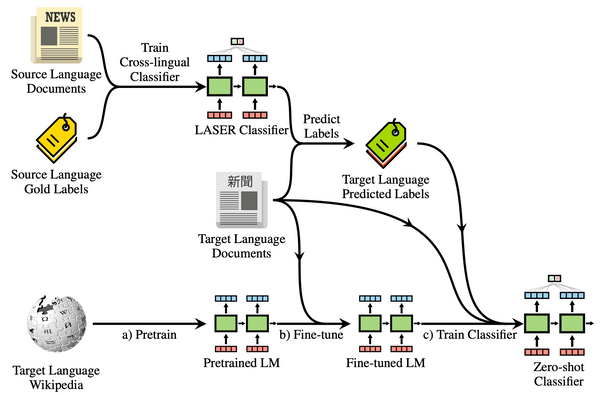
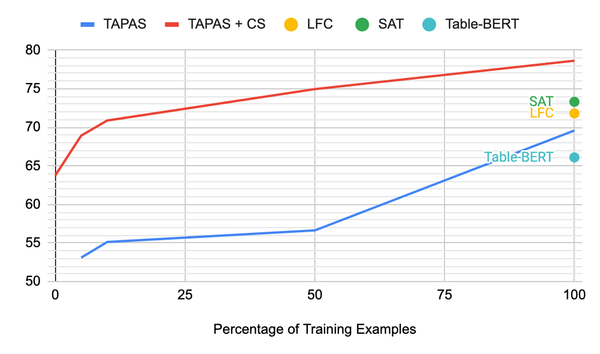
In "Understanding tables with intermediate pre-training", published in Findings of EMNLP 2020, we introduce the first pre-training tasks customized for table parsing, enabling models to learn better, faster and from less data.