Life After Word Embeddings:
Language modeling for transfer learning in NLP
Julian Eisenschlos @eisenjulian
 |
23 de Noviembre de 2018 - LIAA |
Agenda¶
- Transferencia de aprendizaje
- Modelado de lenguaje
- Fine-tuned Transformer Language Model
- Univeral Language Model Fine-Tuning (ULM-FiT)
Slides¶
bit.ly/transfer-nlp

Transferencia de aprendizaje¶
Aprendizaje Supervisado¶
Aproxima una función $f: X\to Y$ a partir de un conjunto de entrenamiento $T \subset X\times Y$ de forma de minimizar una función de error
$$loss(f) = \frac{1}{|T|}\sum_{(x,y)\in T} \ell(f(x), y)$$
Donde $\ell: Y\times Y\to \mathbb{R}$ es una función no negativa de pérdida puntual.
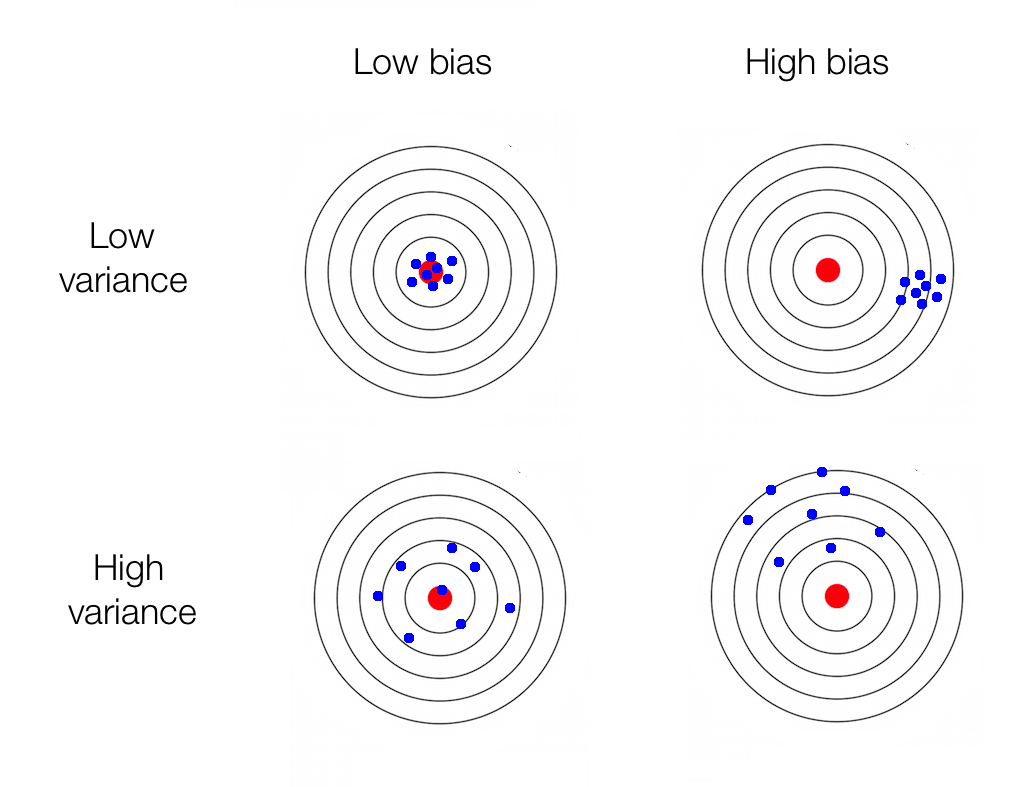
Limitaciones del aprendizaje supervisado¶
- Cantidad de datos de entrenamiento
- El dilema de bias vs. variance
Una breve historia de Computer Vision¶
Representaciones intermedias¶
Una red profunda se puede pensar como una composición de transformaciones diferenciables que factorizan a $f:A\to C$ cómo composición de $2$ o más funciones.
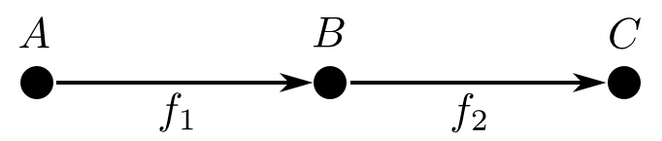
¿Y la transferencia?¶
Estas representaciones intermedias son reusables para otros inputs y otros outputs
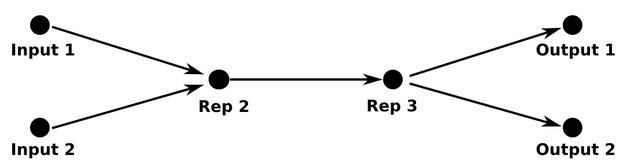
El problema de transfer learning es el olvido catastrófico
Vectores de palabras¶
Los vectores de palabras $W:words\to\mathbb{R}^n$ son el output de la primera capa de una red que tenga palabras como features:
$$W(perro) = (0.1, 0.3, -0.4, ...)$$ $$W(animal) = (0.7, -0.2, -0.1, ...)$$
! pip install --quiet gensim
from gensim.test.utils import common_texts
from gensim.models import FastText
# Train a FastText model
model = FastText(common_texts, size=4, window=3, min_count=1, iter=10)
# Get the vector for a word
model.wv['computer']
3% de mejora en performance
Modelado de lenguaje¶
Un modelo de lenguaje es una distribución $P(w_1, w_2, \cdots ,w_T )$ sobre las secuencias de palabras en $V^n$ en el conjunto de vocabulario $V$.
Vía la regla de la cadena y la hipótesis de Markov, podemos aproximar $P$ como el producto de la probablidad de cada palabra dadas las $n$ anteriores:
$$P(w_1,⋯,w_T)\simeq\prod_ip(w_i|w_{i−1},\cdots,w_{i−n})$$
¿En castellano?¶
Si tengo posibles oraciones, ¿cuál es la más probable?
$$P(``\textrm{Tengo que ir al banco}") > P(``\textrm{Tengo que ir al asiento}")$$
Aplicaciones¶
En principio todo lo que sea generación de lenguage
- Traducciones
- Auto-corrector
- Reconocimiento de audio
- Chatbots
- Question Answering
- Resúmenes
- Y ...
Ejemplos¶
El ejemplo más básico no paramétrico son los modelos basados en $n$-gramas, usando frecuencias de las partes de la oración:
$$P(w_t|w_{t−1},\cdots,w_{t−n})=\frac{count(w_{t−n},\cdots,w_{t−1},w_t)} {count(w_{t−n},\cdots,w_{t−1})}$$
Los ejemplos paramétricos más comunes se basan en un embedding $v:V\to\mathbb{R}^k$, y una función (en general una red neuronal) $f: (w_{t-1}, \cdots, w_{t-n})\to \mathbb{R}^k$ que dado el contexto construye un vector $h$ y con una capa softmax cacula:
$$P(w|w_{t−1},\cdots,w_{t−n})\propto \exp(h\cdot v_w)$$
Una arquitectura común para modelos esto es el uso de redes recurrentes (o RNN), es decir una función recursiva $g$ tal que:
$$f(w_{t-1},\cdots,w_{t-n}) = g(w_{t-1}, g(w_{t-2}, \cdots))$$

Referencia: Understanding LSTMs
Perplejidad¶
¿Cómo evaluamos si un modelo de lenguaje es bueno?
- La mejor forma es con evaluaciones extrínsicas sobre las aplicaciones, sea traducciones, auto-corrector, etc... pero eso es caro
- La medida standard intrínsica es la de minimizar la perplejidad, el exponente de la cross-entropy, que mide cuan bien nuestro modelo aproxima la distribución empírica
$$\exp\left(\frac{1}{|C|}\sum_{(w_1, \cdots, w_n)\in C} -\log\left(P\left(w_n|w_{n-1},\cdots,w_1\right)\right)\right)$$
Como referencia, una variable aleatoria de perplejidad $k$ tiene el mismo nivel de incerteza que un dado de $k$-caras.
Los dos datasets más usados para medir perplejidad son Pen Tree Ban y Wikipedia. Sobre Penn, con un vocabulario de $10,000$ palabras tenemos:
| Modelo | Perplejidad |
|---|---|
| $5$-gramas | 141 |
| LSTM vainilla | 82 |
| AWD-LSTMs | 57 |
¿Cómo generamos texto con modelo de lenguaje? Veamos un ejemplo en PyTorch
model = torch.load('lm.pt')
seed_words = "so it was n't quite what I was expecting , but I really liked it ! The best".split()
# Input is a PyTorch recurrent model
def init_model(model, seed_words):
hidden = model.init_hidden(1)
input = torch.tensor([[0]], dtype=torch.long).to(device)
# Iterate through the seed words to set the model state
for word in seed_words:
print(word, end=' ')
word_idx = corpus.dictionary.word2idx[word]
input.fill_(word_idx)
output, hidden = model(input, hidden)
return hidden
hidden = init_model(model, seed_words)
def sample_model(model, hidden, temperature=1.0, length=50):
input = torch.tensor([[0]], dtype=torch.long).to(device)
# Generate new words based on the language model and the temperature
for i in range(length):
output, hidden = model(input, hidden)
word_weights = output.squeeze().div(temperature).exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
input.fill_(word_idx)
word = corpus.dictionary.idx2word[word_idx]
print(word, end=' ')
sample_model(model, hidden)
> so it was n't quite what i was expecting , but i really liked it ! the best ... film ever ! <eos> i saw this movie at the toronto international film festival . i was very impressed . i was very impressed with the acting . i was very impressed with the acting . i was surprised to see that the actors were not in the movie .Más aplicaciones¶
¡Gracias a los modelos de lenguaje, todo el texto de internet puede ser el ImageNet para NLP!
¿Cómo usamos el modelos de lenguaje para mejorar la performance en tareas cómo clasificación?

Fine-tuned Transformer Language Model¶
El modelo Transformer de Vaswani et al fue introducido en 2017. Se basa principalemente en selt-attention basada en contenido y posición.
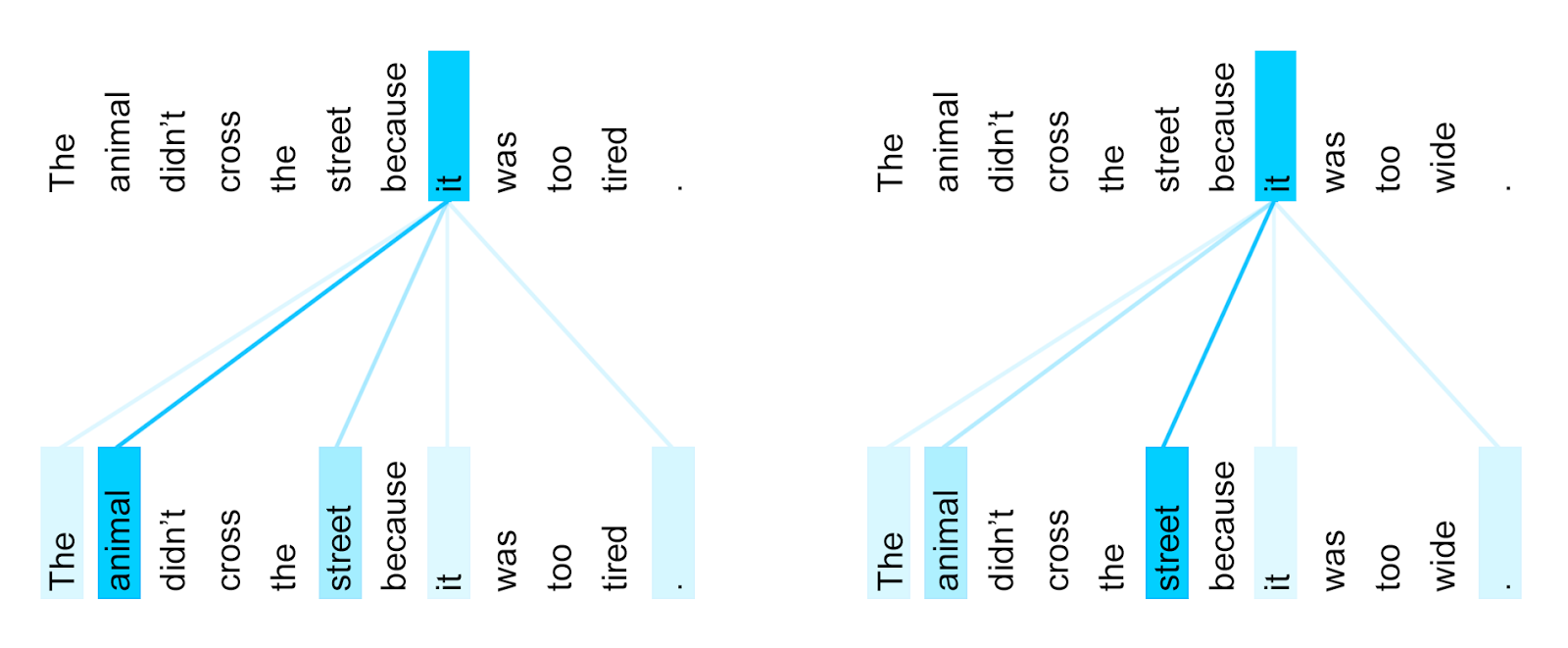
La atención es la versión diferenciable de acceder a un dato en un key-value storage
$$\textrm{Attention}\left(Q,K,V\right)=\textrm{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V$$
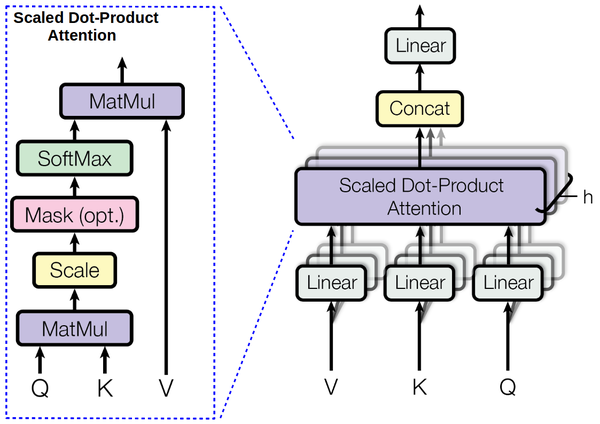
Originalmente usaron esta arquitectura para traducción, mejorando el SOTA para el WMT Benchmark de traducciones del inglés al alemán y al francés. Ver el código en github
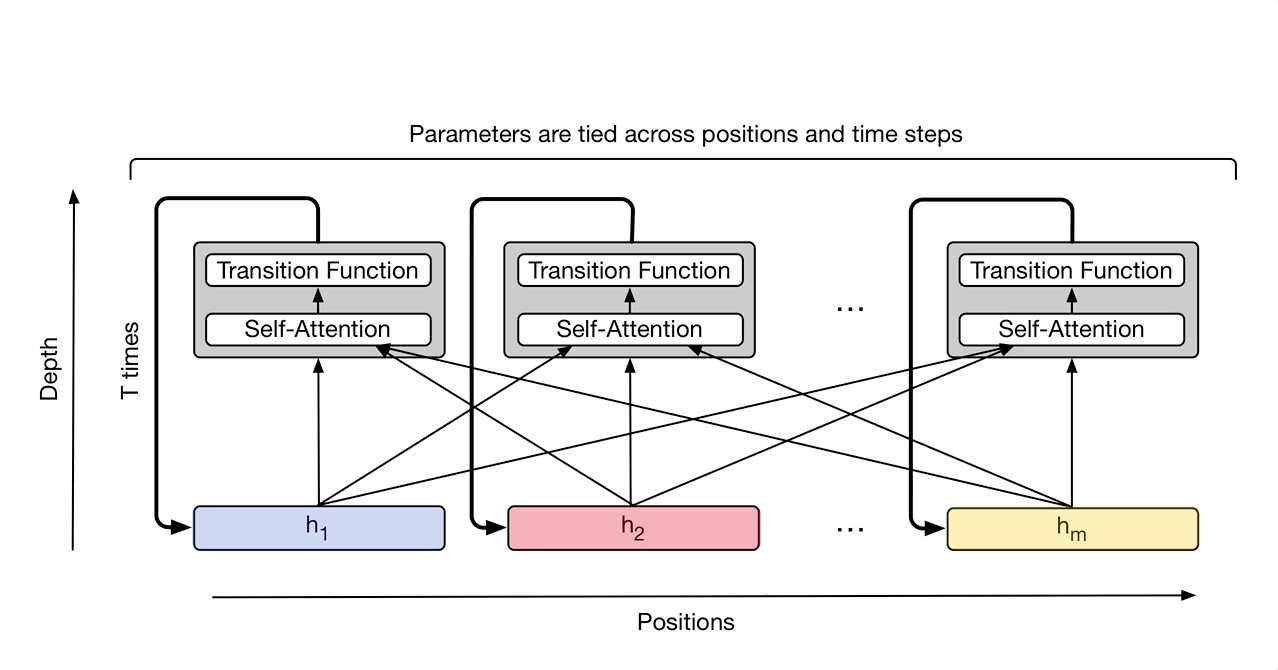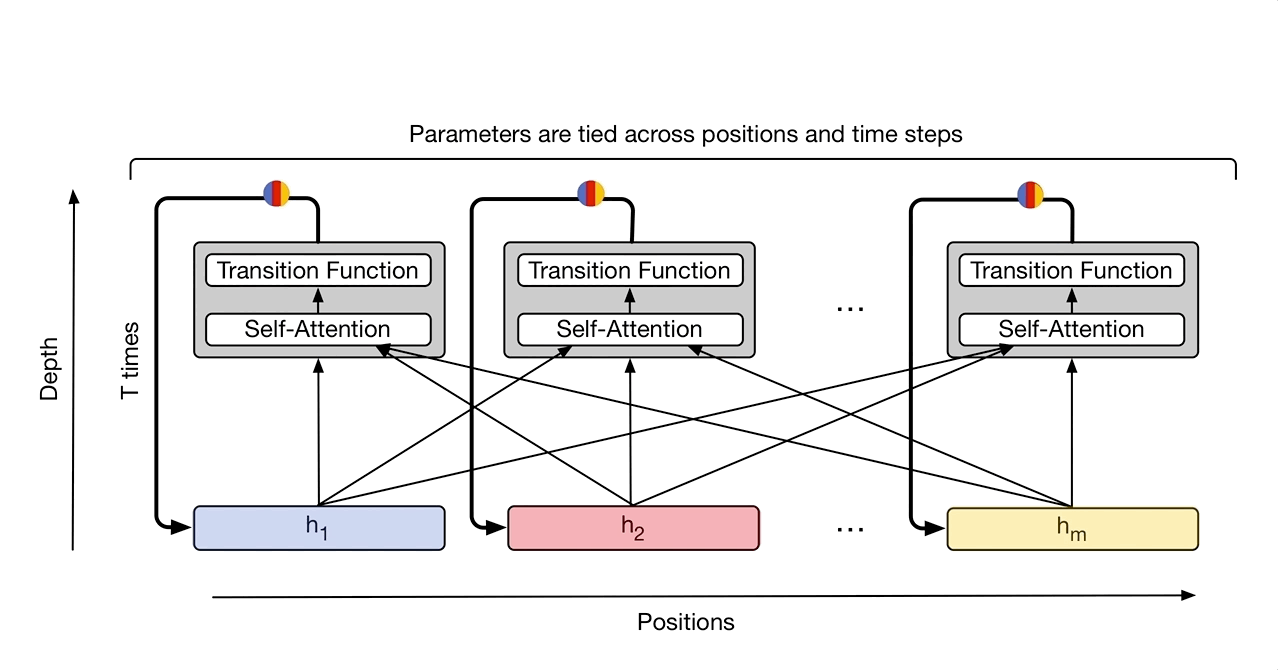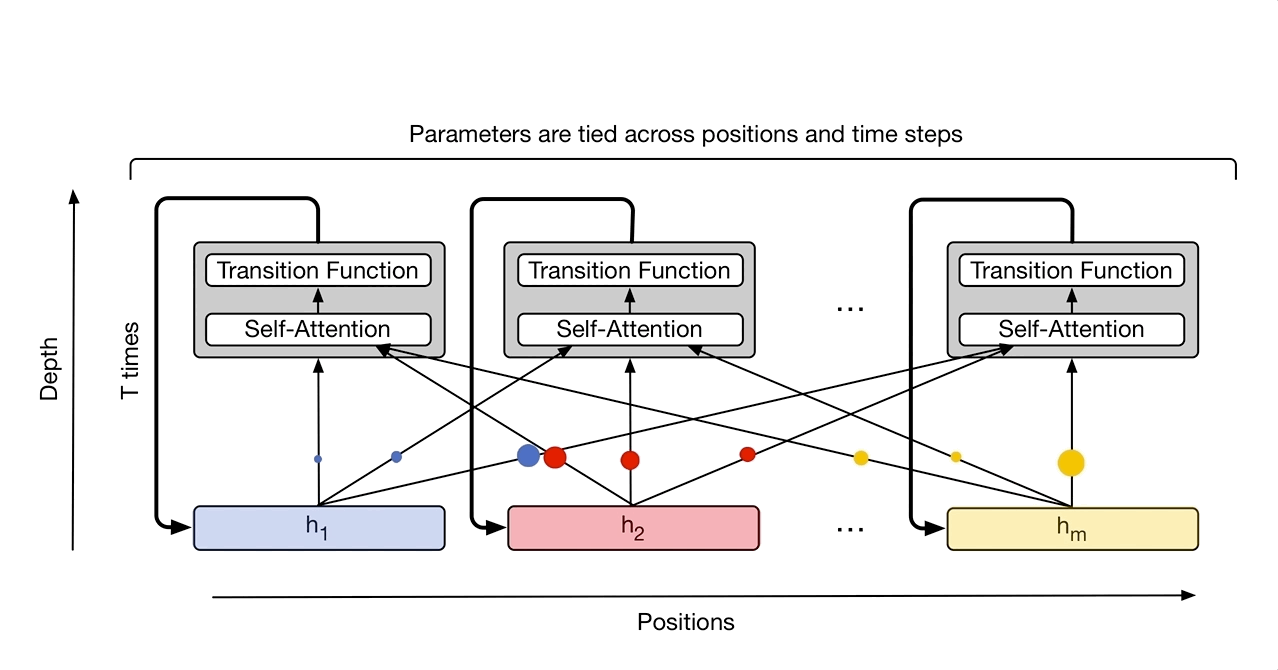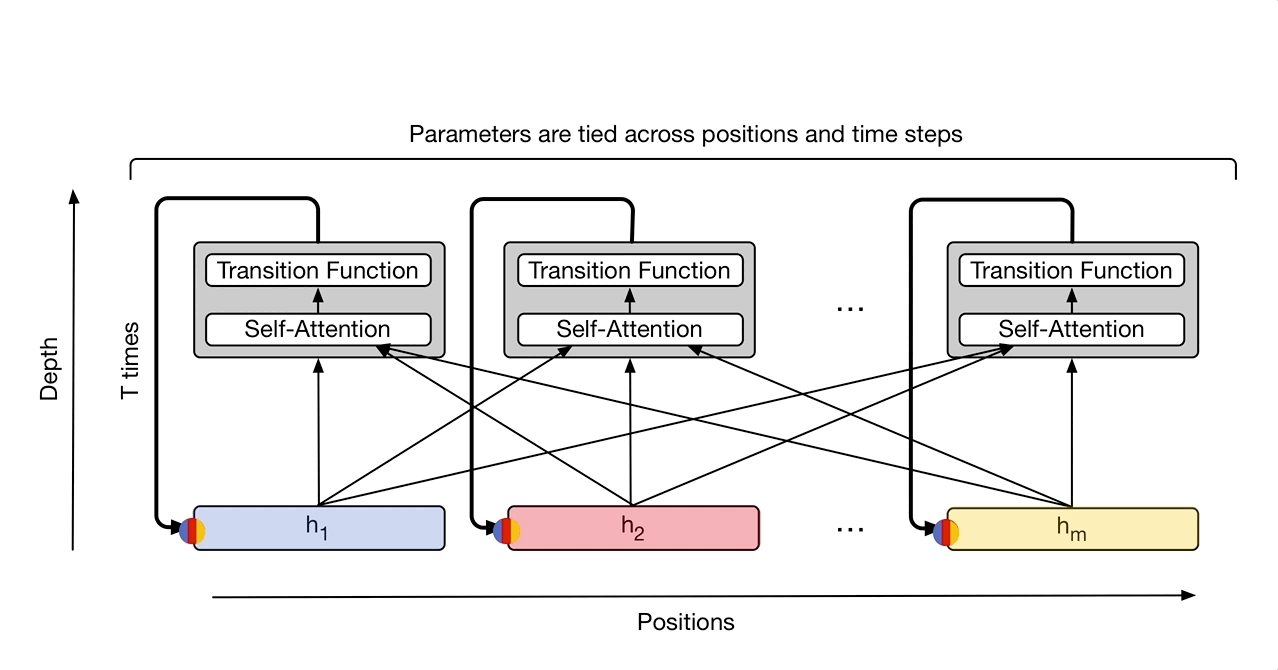
Nota: esta imagen es de una siguiente iteración llamada Universal Transformer.
A mitad de 2018, Alec Radford et al usaron transformers pre-entrenados usando modelos de lenguaje para muchas otras tareas clásicas de NLP con resultados muy buenos en casi todas
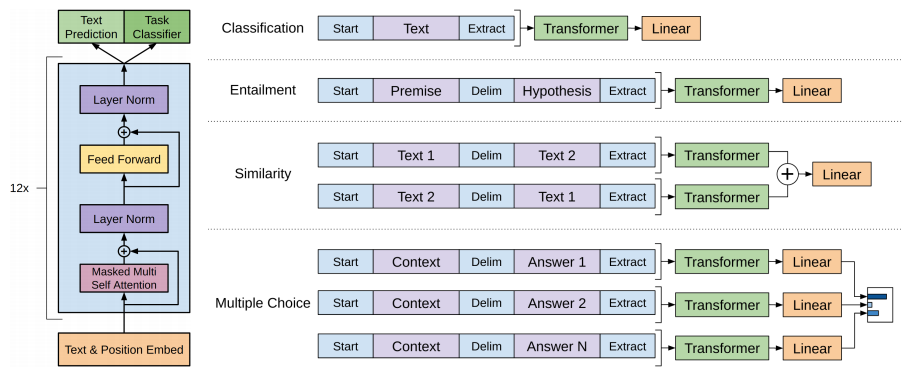
Se puede ver el código y el modelo entrenado en https://github.com/openai/finetune-transformer-lm
Universal Language Model Fine Tuning (ULM-FiT)¶
Jeremy Howard y Sebastian Ruder propusieron ULM-FiT a principios de 2018, con la idea de aplicar eficientemente modelos de lenguaje como base para otras tareas de NLP
Las ideas principales son:
- Partir de un modelo de lenguaje genérico
- Re-entrenarlo en el dominio particular de mis datos (inclusive si no están todos etiquetados!)
- Usar la última capa del modelo para otras tareas independientes con 2 capas lineales + ReLu sobre el output de la LSTM
Las técnicas principales son:
- AWD-LSTMs = LSTM clásico + magias para regularizar
- DropConnect: Dropout a fijo a lo largo de todas las iteraciones de la red recursiva
- Una variante de Averaged Stochastic Gradient Descent
- Gradual Unfreezing
- Discriminative Fine Tuning
- Slanted Triangular Learning Rates
Con $100$ ejemplos se logran resultados que antes necesitaban $20$ mil!
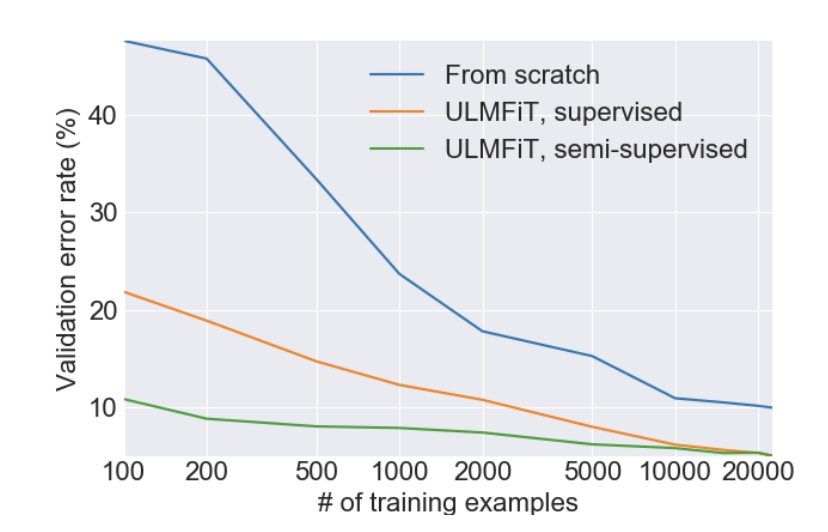
Resultados¶
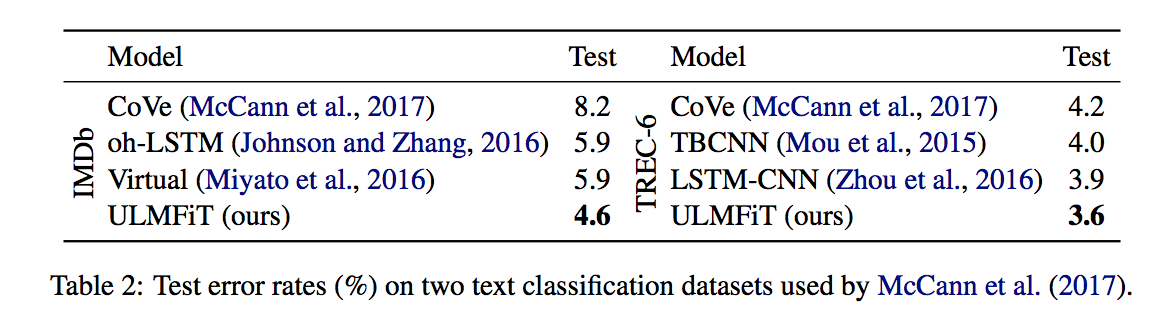
Y alcanza con Wikipedia en cualquier idioma para entrenarlo
$LANG = 'es'
# Install Fast.ai it might take a bit
git clone https://github.com/fastai/fastai.git && cd fastai && pip install .
cd fastai/courses/dl2/imdb_scripts/
# Get spacy in your language
pip install spacy
python -m spacy download $LANG
bash prepare_wiki.sh
python pretrain_lm.py data/wiki/$LANG/ --cuda-id 0 --lr 1e-3 --cl 12
# We just need train and val csv files as well a pretrained language model
python fastai/courses/dl2/imdb_scripts/create_toks.py $DATA_PATH --lang $LANG
python fastai/courses/dl2/imdb_scripts/tok2id.py $DATA_PATH
python fastai/courses/dl2/imdb_scripts/finetune_lm.py $DATA_PATH wt103/$LANG --cuda-id 0 --cl 25
python fastai/courses/dl2/imdb_scripts/train_clas.py $DATA_PATH --cuda-id 0 --cl 50
Pasando en limpio¶
- Los modelos de lenguaje, ¿pueden ser el ImageNet para NLP?
- OpenAI Transformer Language Model
- Se basa en self-attention en lugar de RNNs
- Entrena conjuntamente el LM junto con la tarea específica
- Consigue mejores resultados en otras tareas más allá de clasificación
- Lento de entrenar (1 mes en 8 GPUs)
- ULMFiT
- Se basa modelos de lenguaje AWD-LSTMs
- Usa learning rates discriminativos
- Hay datos uniformes en casi todos los idiomas
- Más rápido de entrenar
- ¡Ambos modelos y código son públicos!
Próximos pasos¶
- Liberar los modelos pre-entrenados en muchos más idiomas
- Aplicar las misma arquitectura a otras tareas además de clasificación
- Entrenar modelos de lenguaje en varios idiomas simultaneamente
Referencias¶
- Regularizing and Optimizing LSTM Language Models by Merity et al introdues AWD-LSTM Networks
- Attention Is All You Need by Vaswani et al introduces the Transformer
- Universal Language Model Fine-tuning for Text Classification by Ruder and Howard introduces ULMFiT
- Improving Language Understanding by Generative Pre-Training by Radford introduces a transformer LM-based geneeral NLP framework